Title: A Section of the Via Sacra, Rome (The Church of Saints Cosmas and Damian)
Creator: Christoffer Wilhelm Eckersberg
Date Created: ca. 1814–15
Physical Dimensions: 12 3/8 x 17 1/8 in. (31.4 x 43.5 cm)
Type: Painting
Medium: Oil on canvas
Repository: Metropolitan Museum of Art, New York, NY
需求
爬取拉勾网成都地区机器学习算法岗位的相关信息,为后期数据分析、词云展示做数据准备
问题
- 网上某些基于json数据直接下载的方法已经失效,拉勾采取了比较多的反爬机制
- 连续请求10次职位详情,就会弹出登录页面。不管直接发请求还是人为点击,均触发该机制
- 请求过快也会弹出登录页面,需要模拟人为操作的时间间隔
解决方案
- 不直接基于json数据进行爬取,采用selenium调用浏览器driver,模拟真实用户使用浏览器进行访问爬取
- 连续10次请求后,重启浏览器,继续爬取,避免登录。从而实现免登陆爬取数据
- 在所有请求操作中,均设置sleep间隔时间,避免请求过快弹出登录页面
- 实现中需调用chrome浏览器,需要把对应版本的chromedriver.exe放入到工作目录中
代码实现
本项目主要使用的model:
- webdriver :用于自动启动浏览器,并进行有关操作
- lxml :进行网页解析
- random :生成随机数,用于在一定范围内sleep
- time :用于sleep
- pandas :用于数据存储和处理
完整代码如下,代码注释个人觉得比较详细了,就不做代码解读
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
from selenium import webdriver
from lxml import etree
import random
import time
import pandas as pd
class LagouSpider():
def __init__(self, keyword, city):
self.driver = webdriver.Chrome()
self.keyword = keyword
self.city = city
self.url = "https://www.lagou.com/jobs/list_" + self.keyword + "?px=default&city=" + self.city + "##filterBox"
self.all_links = []
## 特性
self.company_name = [] ## 公司名
self.company_domain = [] ## 领域
self.company_scale = [] ## 规模
self.company_financing = [] ## 融资
self.position_address = [] ## 区域
self.position_name = [] ## 职位名称
self.salary = [] ## 薪资
## self.city = []
self.work_year = [] ## 工作年限
self.education = [] ## 学历
self.advantage = [] ## 职位诱惑
self.bt_detail = [] ## 岗位职责和要求
def restart_brower(self):
self.driver.close()
self.driver.quit()
self.driver = webdriver.Chrome()
def request_detail_times(self, ten_links):
'''
鉴于问题2,这里每次对10个职位详情进行遍历请求,保存数据后,然后关闭浏览器
鉴于问题3,每次对1个职位详情请求后,sleep几秒
'''
for link in ten_links:
self.get_detail_page(link) ## 获取每一个链接中的详细信息
print(link + '...done\n')
time.sleep(random.randint(1, 5))
def get_all_detail_links(self):
'''
根据url获取all links
'''
self.driver.get(self.url)
page_num = 1
while True:
source = self.driver.page_source
html = etree.HTML(source)
links = html.xpath('//a[@class="position_link"]/@href')
self.all_links += links ## 获取的links存放在self.all_links中
try:
next_btn = self.driver.find_element_by_xpath(
'//div[@class="pager_container"]/span[last()]')
if next_btn == None or "pager_next_disabled" in next_btn.get_attribute("class") or page_num >= 10:
## 不存在下一页按钮或者下一页不可用,则退出浏览器
## self.driver.close()
return list(set(self.all_links))
else:
## 下一页可用,则点击下一页
next_btn.click()
page_num += 1
time.sleep(random.randint(1, 5))
except:
return list(set(self.all_links))
time.sleep(random.randint(1, 5))
return self.all_links
def get_detail_page(self, link):
'''
获取link中的详细职位描述等信息,并保存
'''
print(link)
self.driver.get(link)
source = self.driver.page_source
## 解析页面
html = etree.HTML(source)
## 获取职位名称
position_name = html.xpath(
'//div[@class="job-name"]/@title')[0]
self.position_name.append(position_name)
## 获取职位id
position_id = html.xpath(
'//link[@rel="canonical"]/@href')[0].split('/')[-1].replace('.html', '')
## 获取薪资
job_request_spans = html.xpath('//dd[@class="job_request"]//span')
salary = job_request_spans[0].xpath('.//text()')[0].strip()
self.salary.append(salary)
## 获取城市
## city = job_request_spans[1].xpath(
## './/text()')[0].strip().replace('/', '').strip()
## self.city.append(city)
## 获取工作年限
work_year = job_request_spans[2].xpath(
'.//text()')[0].strip('/').strip()
self.work_year.append(work_year)
## 获取学历要求
education = job_request_spans[3].xpath(
'.//text()')[0].strip('/').strip()
self.education.append(education)
## 获取职位诱惑
job_detail_dl = html.xpath('//dl[@class="job_detail"]')[0]
advantage = job_detail_dl.xpath(
'.//dd[@class="job-advantage"]//p/text()')[0].strip('/').strip().replace(",", ",")
self.advantage.append(advantage)
## 获取岗位职责和要求
bt_detail = "".join(job_detail_dl.xpath('.//div[@class="job-detail"]')[0].xpath('.//text()')).strip().replace(" ", "").replace("\n", "")
## print(bt_detail)
self.bt_detail.append(bt_detail)
## 获取区域
position_address = html.xpath(
'//div[@class="work_addr"]//a')[1].xpath('.//text()')[0].strip()
self.position_address.append(position_address)
## 获取公司名称
company_name = html.xpath(
'//em[@class="fl-cn"]//text()')[0].strip()
self.company_name.append(company_name)
## 获取领域
company = html.xpath('//h4[@class="c_feature_name"]//text()')
company_domain = company[0]
self.company_domain.append(company_domain)
## 获取融资
company_financing = company[1]
self.company_financing.append(company_financing)
## 获取规模
company_scale = company[2]
self.company_scale.append(company_scale)
def save_csv(self):
## 退出浏览器并关闭driver
self.driver.quit()
## 写入csv文件中
## 字典中的key值即为csv中列名
## 公司、领域、融资、规模、区域、职位、薪资、工作年限、学历、职位诱惑、岗位职责和要求
dataframe = pd.DataFrame({'公司': self.company_name, '领域': self.company_domain, '融资': self.company_financing,
'规模': self.company_scale, '区域': self.position_address,
'职位': self.position_name, '薪资': self.salary, '工作年限': self.work_year,
'学历': self.education, '职位诱惑': self.advantage, '岗位职责和要求': self.bt_detail})
## 将DataFrame存储为csv,index表示是否显示行名,default=True
file_name = self.keyword + "_" + self.city + ".csv"
dataframe.to_csv(file_name, index=False, sep=',')
主要功能实现已经完成,下面进行调用并保存结果到csv
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def main():
city = "成都"
keyword = "机器学习算法"
lg = LagouSpider(keyword, city)
all_links = lg.get_all_detail_links()
all_links = [all_links[i:i+10] for i in range(0, len(all_links), 10)]
for ten_links in all_links:
lg.request_detail_times(ten_links)
time.sleep(random.randint(5, 10))
lg.restart_brower()
lg.save_csv()
main()
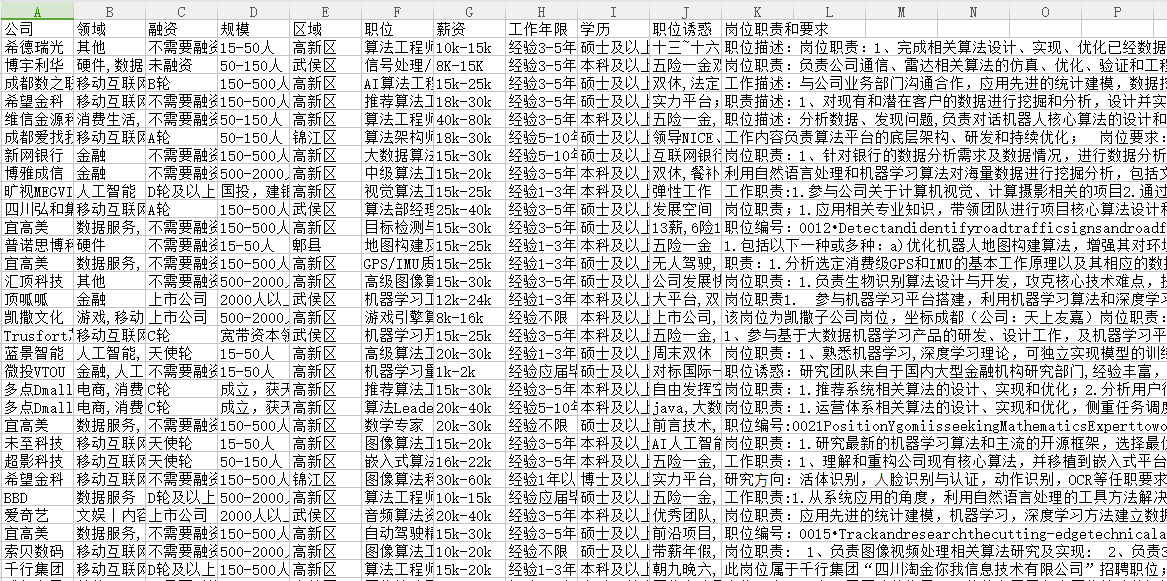
结果
抓取结果如下图: