Title: Ulysses and the Sirens
Creator: John William Waterhouse
Creator Lifespan: 06 April 1849 - 10 February 1917
Creator Nationality: English
Creator Gender: Male
Creator Death Place: London, England
Creator Birth Place: Rome, Italy
Date Created: 1891
Physical Dimensions: 100.6 x 202.0 cm (Unframed)
Type: Paintings
Medium: oil on canvas
前言
声纹识别是一种生物特征识别技术,通过分析和识别个体的声音特征来确定其身份。随着技术的发展,声纹识别被广泛应用于安全验证、智能助手等领域。我工作所在的行业也进行了大量的应用。
然而,随着应用的普及,其安全性问题也日益凸显。作为前瞻性的安全实验室,我们有责任深入研究声纹识别的安全攻防。本文将介绍声纹识别的技术基础,为后续的安全攻防奠定基础。
基本概念
声纹识别(VPR),也称说话人识别(Speaker Recognition),是根据人的声波特性进行身份辨识的服务。可以将说话人声纹信息与库中的已知用户声纹进行 1:N 比对验证和 1:1 的检索。具有识别准确率高,操作简单快捷,对终端要求低,获取方便自然,隐蔽性较强等特点,广泛应用于金融认证、智能家居、安防等领域。
1 vs. N 表示说话人识别,(1 vs.1)表示说话人鉴别。说话人识别:训练阶段对每个已知的说话人建立参数模型;识别阶段将未知语音与存在的模型进行一一比较,最后根据结果作出判决。说话人鉴别:训练阶段对每个已知的说话人建立参数模型;识别阶段待确认说话人的语音首先与其声明的身份参数模型进行比较,然后与所有背景说话人参数模型作对比,根据两次预测值的比值与特定阈值进行比较,做出真或假的判决。
声纹识别的原理如下图所示,目标说话人的语音先做特征提取,然后进行声纹建模,验证语音也要经过特征提取,才能进行声纹比对。声纹得分与事先设定的阈值比对,最后得到验证结果。
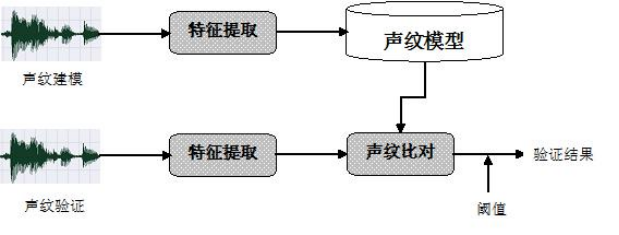
以上原理图是一个典型的模式识别过程,关键是采集话语语音(信号采集)、找到有效语音(数据预处理和特征提取)、建立声纹模型(算法模型)、进行模型对比(得分分析),最后给出对比结果。
接下来,本文将从上述步骤进行逐一分析。
信号采集
声音信号的捕获是声纹识别的基础,涉及声波的物理特性、捕获设备、数字化过程和信号处理等多个环节。通过高质量的声音捕获,系统能够获取准确的音频数据,为后续的特征提取和声纹识别打下坚实基础。
常见的采样设备包括麦克风咪头和麦克风阵列两种。
麦克风咪头
- 单个麦克风组件,可以是动圈、电容或 MEMS 等类型
- 声音捕获范围有限,通常只能捕捉其正前方的声音(依赖于指向性设计)
- 需要外部处理器来增强信号和去噪
- 对背景噪声的抵抗力较弱,尤其是全指向麦克风
-
结构简单,使用方便,成本较低
麦克风阵列
- 由多个麦克风组成的系统,可以是动圈、电容或MEMS类型
- 能够捕捉来自多个方向的声音,具备更强的空间感知能力
- 可以通过相位差和时间延迟来定位声源,提高噪声抑制效果
- 通过信号处理算法(如波束形成)来减少背景噪声,增强目标声源
-
结构复杂,通常需要更多的处理器和算法支持,成本较高

信号预处理
声纹信号的预处理是声纹识别和语音识别系统中的关键步骤,旨在提高后续特征提取和识别的准确性。以下是一些常用的预处理技术。
去噪
- 频谱减法噪声:通过估计噪声频谱,并从语音信号的频谱中减去相应的噪声成分
- Wiener滤波:自适应滤波器,根据信号的统计特性动态调整频率响应,以减小噪声
归一化
- 幅度归一化:将信号的幅度缩放到一个固定范围(如[-1, 1])
- Z-score标准化:计算信号的均值和标准差,将信号转换为均值为0、标准差为1的分布
预加重
- 一阶差分:通过加权当前样本与前一样本的差值,形成新的信号。常用的预加重系数为0.97
平滑处理
- 移动平均:通过计算信号的移动平均值来平滑信号
- 中值滤波:使用滑动窗口计算中值,去除极端噪声对信号的影响
特征提取
特征提取是语音信号处理中的关键步骤,目的是将原始的语音信号转换为更具代表性的特征,以便于后续的分类和识别。
这里主要介绍一种传统的 MFCC 和 一种谷歌2014年提出基于深度学习的 D-vector。
MFCC (Mel频率倒谱系数)
MFCC(Mel-Frequency Cepstral Coefficients)是一种常用的语音特征参数,它通过模拟人耳对声音的感知特性,提取出适合于语音分析的重要特征。
MFCC的提取过程可以分为以下几个步骤:
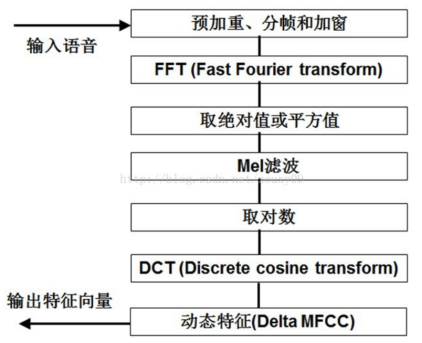
预加重
增强高频成分,补偿声道特性引起的高频衰减。计算过程:
通常使用一阶差分公式: [ y[n] = x[n] - \alpha \cdot x[n-1] ] 其中,( \alpha ) 通常取值为0.95。
分帧
将连续的语音信号分割成短时信号,便于分析。常见的帧长为20-30毫秒,帧移一般为10毫秒。
加窗
减少帧边界处的失真,平滑信号。常用窗函数:汉明窗、汉宁窗等。
傅里叶变换
将时域信号转换到频域。计算:使用快速傅里叶变换(FFT)计算每一帧的频谱。
Mel滤波器组
模拟人耳对频率的感知,将频谱转换到Mel尺度。计算过程:
1)选择若干个Mel滤波器(通常是20-40个),这些滤波器在Mel尺度上均匀分布。
2)通过滤波器对频谱进行加权,得到每个滤波器的能量。
对数运算
压缩能量范围,降低大幅度变化的影响。计算:
对每个滤波器的能量取对数: [ L[i] = \log(E[i]) ] 其中,( E[i] ) 是第( i )个滤波器的能量。
离散余弦变换(DCT)
将对数能量转换为MFCC,减少特征间的相关性。计算:
对对数能量进行DCT,得到MFCC系数: [ C[k] = \sum_{n=0}^{N-1} L[n] \cos\left(\frac{\pi k}{N} \left(n + \frac{1}{2}\right)\right) ] 其中,( N ) 是滤波器的数量,( C[k] ) 是第( k )个MFCC系数。
D-vector
D-vector 是一种基于深度学习的特征提取方法,它通过深度神经网络(DNN)提取说话人的特征向量(即 D-vector),这种特征向量能够有效区分不同说话人的声音特征。
D-vector 提取的特征向量相较于传统方法(如 MFCC)在识别准确率和效率上有显著提升,对环境噪声和说话风格变化具有较强的鲁棒性。此外,它还可以通过训练不同的模型扩展到新的说话人,无需重新设计特征提取过程。
D-vector 的提取通常包括以下几个步骤:
数据预处理
- 语音信号处理:首先,对原始语音信号进行预处理,包括去噪、归一化、端点检测等步骤。
- 特征提取:通常使用 MFCC 或 PLP 等传统特征作为输入。
网络结构设计
- 深度神经网络(DNN):D-vector 网络通常采用深层神经网络结构,网络由多个全连接层构成。
- 输入层:输入层接受经过特征提取的语音特征(如 MFCC)。
- 隐藏层:多个隐藏层用于学习复杂的非线性特征映射。
- 输出层:
- 说话人标签:用于多分类任务,识别特定说话人。
- 特征输出:通过最后一层提取说话人的特征向量。
训练过程
- 损失函数:通常采用交叉熵损失函数,优化说话人分类任务。
- 反向传播:使用反向传播算法更新网络权重,以最小化损失。
- 数据增强:通过增加数据集的多样性(如添加噪声、时间扭曲等),提高模型的鲁棒性。
特征提取
- D-vector 生成:训练完成后,网络的最后一层输出的特征向量即为 D-vector。该向量通常具有固定的维度(如 256 或 512),能够有效表示说话人的特征。
算法模型
注:语音和声纹识别算法模型实际对数学和信号处理的要求较高,本文只做最基本的科普和流程介绍,读者如有兴趣可自行搜索,目前这块算法都较为成熟,资料较多。
在我的工作经验看来,目前算法模型已经优化的足够了,难点在于远场语音的拾音去噪增强等导致效果很差,近场语音和声纹普通使用基本无障碍。
高斯混合模型(GMM)
高斯混合模型(Gaussian Mixture Model, GMM)是一种常用的概率模型,用于表示具有多个高斯分布的任意复杂分布。GMM在声纹识别中主要用于建模和区分不同说话人的声音特征。
- 混合模型:GMM由多个高斯分布的线性组合组成。每个高斯分布称为一个“成分”。
- 概率密度函数:GMM的概率密度函数可以表示为:
[
P(x) = \sum_{k=1}^{K} \pi_k \cdot \mathcal{N}(x | \mu_k, \Sigma_k)
]
其中:
- ( K ):高斯成分的数量。
- ( \pi_k ):第 ( k ) 个成分的权重,满足 ( \sum_{k=1}^{K} \pi_k = 1 )。
-
( \mathcal{N}(x \mu_k, \Sigma_k) ):第 ( k ) 个高斯分布的概率密度函数,具有均值 ( \mu_k ) 和协方差矩阵 ( \Sigma_k )。
- 均值(Mean):每个成分的中心点,表示该高斯分布的“位置”。
- 协方差(Covariance):描述数据的分布范围和形状,反映特征之间的相关性。
- 权重(Weights):每个成分在整体模型中的重要性。
声纹识别通常包括以下几个步骤:
特征提取
- 音频信号处理:首先,对原始音频信号进行预处理,如去噪、分帧等。
- 特征提取:使用MFCC(Mel频率倒谱系数)或其他特征提取方法,提取出每个音频片段的声学特征。
构建GMM模型
- 训练数据准备:收集每个说话人的语音样本,并提取相应的声学特征。
- GMM训练:
- 使用EM算法训练一个GMM,模型的每个成分对应于说话人声音特征的一个分布。
- 训练过程中,模型学习每个说话人的声学特征的均值、协方差和权重。
模型表示
- 每个说话人都有一个对应的GMM,这个模型用于表示其特征分布。GMM可以有效捕捉声音特征的多样性和复杂性。
似然计算
- 在识别阶段,计算待识别语音片段在各个说话人GMM模型下的似然概率: [ P(x | \text{GMM}) = \sum_{k=1}^{K} \pi_k \cdot \mathcal{N}(x | \mu_k, \Sigma_k) ] 其中,( x ) 是待识别的特征向量。
识别决策
- 将待识别样本的似然概率与所有说话人模型的似然概率进行比较,选择概率最高的说话人作为识别结果。
高斯混合模型-通用背景模型(GMM-UBM)
高斯混合模型 GMM-UBM(Gaussian Mixture Model - Universal Background Model)是声纹识别中一种常用的技术,旨在提高说话人识别的准确性和鲁棒性。该方法结合了通用背景模型和说话人特定模型的优点。
GMM-UBM 的基本概念
- 通用背景模型(UBM):一个代表了所有说话人语音特征的高斯混合模型,通常通过大量不同说话人的数据训练而成。
- 说话人模型:每个说话人的特定模型,通过在通用背景模型的基础上进行调整来适应其声音特征。
GMM-UBM 的工作流程
训练通用背景模型(UBM)
1)数据收集:收集大量说话人的语音样本,确保样本的多样性。
2)特征提取:对所有样本提取MFCC等声学特征。
3)GMM训练:使用EM算法训练一个通用背景模型(UBM),此模型包含多个高斯成分,能够捕捉到多种声音特征的分布。
训练说话人特定模型
1)数据收集:收集特定说话人的语音样本。
2)特征提取:对特定说话人的样本提取声学特征。
3)模型适应:使用UBM对说话人特定模型进行适应,通常通过MAP(最大后验估计)方法: [ P(\theta_s | D) \propto P(D | \theta_s) P(\theta_s | \theta_{ubm}) ] 其中,( \theta_s ) 是说话人模型的参数,( D ) 是说话人数据,( \theta_{ubm} ) 是UBM的参数。
识别阶段
1)特征提取:对待识别的语音进行特征提取。
2)计算似然概率:计算待识别样本在每个说话人模型下的似然概率,并与UBM的似然概率进行比较。
3)决策:选择似然概率最高的说话人作为识别结果。
UBM 的一个重要的优势在于它是通过最大后验估计(Maximum A Posterior,MAP)的算法对模型参数进行估计,避免了过拟合的发生。MAP算法的另外一个优势是我们不必再去调整目标用户GMM的所有参数(权重,均值,方差)只需要对各个高斯成分的均值参数进行估计,就能实现最好的识别性能。UBM平均每个混合得到100帧左右训练样本时,能够获得较高且较稳定识别率。
但是,待估参数还是太多了,检测时需要输入的语音片段太长,不符合实际使用需求。GMM-UBM缺乏对应于信道多变性的补偿能力,直白点说就是它不抗干扰。UBM受训练时长、混合度、信道类型、男女比例等因素影响比较大。
I-vector
GMM-UBM系统对于跨信道识别能力弱,且无法克服信号中的干扰因素,导致系统性能不稳定。由于该模型只改变均值,不改变权重和协方差。在GMM的均值矢量中,既蕴含说话人信息,也有信道信息,虽然均值含有说话人的大多数信息,但对跨信道的语音信号识别性差。
联合因子分析(JFA)则把GMM-UBM模型中的话者差异和信道差异单独建模,并对信道差异实施补偿,获得良好的性能,但JFA的训练对话者说话环境要求极大,需要不同的信道等,训练复杂,实际使用中难以普及。
基于此,Dehak N在JFA的基础上提出了i-vector,用来捕捉说话人差异与信道差异。I-Vector是对话者信号中的全变量建模,即通过一个包含话者个性信息和信道信息的全变量空间进行建模,代替了JFA分别对说话人差异空间和信道空间进行建模,放宽了话者语音环境模型训练的限制。对于I-Vector矢量,可以通过众多信道补偿技术来实现对信道信息的削弱,提高I-Vector说话人确认性能。
目前常见的 I-vector 模型框架:
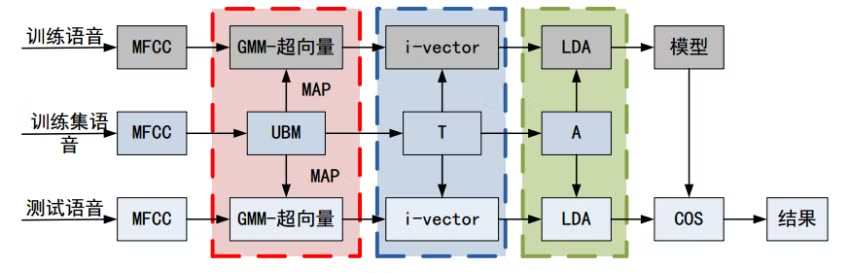
I-vector 的生成过程主要包括以下几个步骤:
特征提取
- 使用 MFCC 或 PLP 等技术从音频信号中提取声学特征。
GMM-UBM 训练
- 通用背景模型(UBM):首先,训练一个通用背景模型(GMM-UBM),用于表示所有说话人的声学特征。
- GMM 训练:使用大量说话人的数据训练 GMM,以捕捉音频特征的分布。
生成 I-vector
- 特征映射:通过使用 GMM 的后验概率,将声学特征映射到一个低维的 I-vector 空间。I-vector 的生成通常通过以下步骤实现:
- 使用 GMM 的成分的后验概率计算每个特征帧的权重。
- 将这些权重结合到一个低维的隐变量空间,生成一个固定长度的 I-vector。
I-vector 的数学表示
I-vector 的生成可以表示为: [ \mathbf{y} = \mathbf{A} \mathbf{x} + \mathbf{n} ] 其中:
- ( \mathbf{y} ) 是 I-vector。
- ( \mathbf{A} ) 是一个映射矩阵。
- ( \mathbf{x} ) 是声学特征。
- ( \mathbf{n} ) 是噪声项。
深度神经网络
注:深度神经网络本文中主要展示目前业务的算法模型和测试成绩
延时深度网络(TDNN)
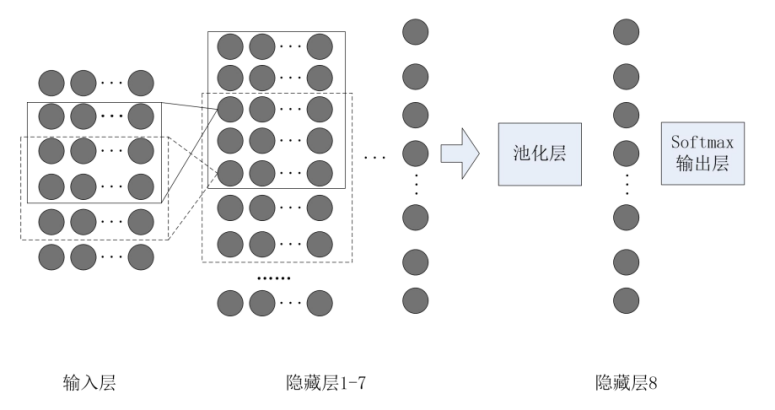

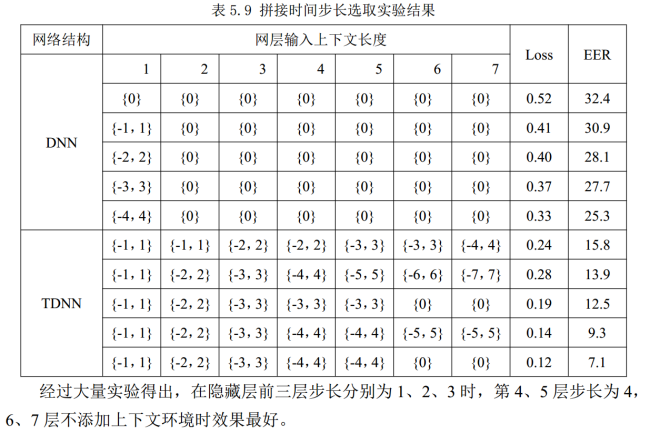
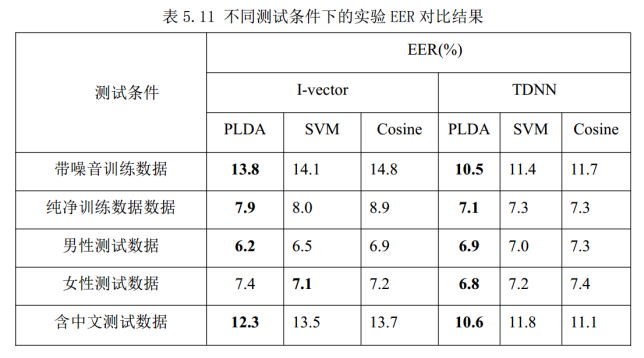
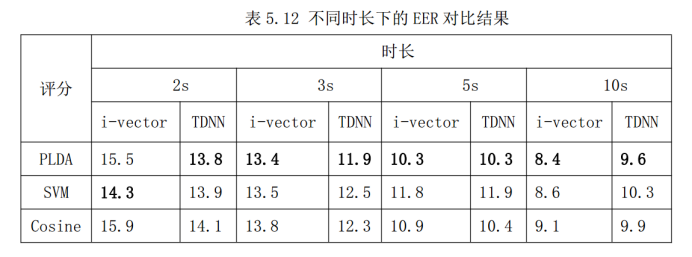
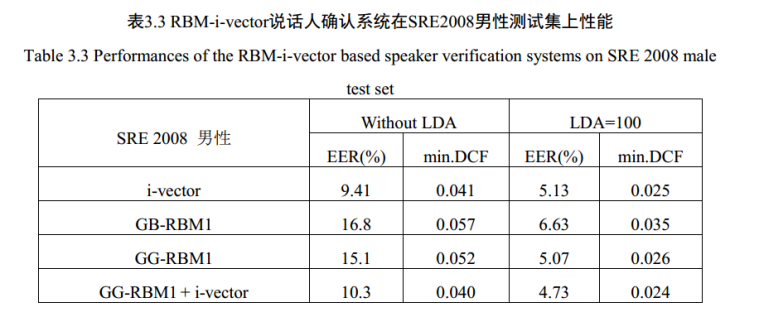
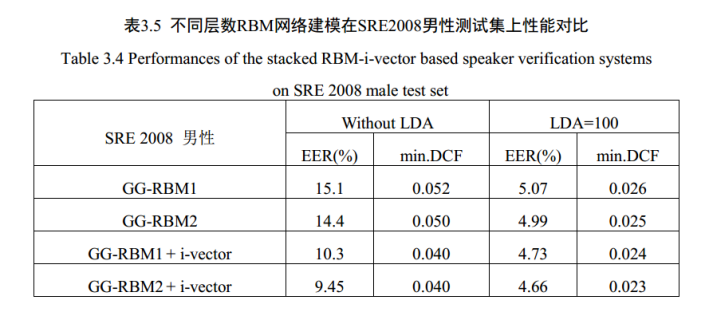
深度置信网络—堆叠受限波尔兹曼机(RMB)
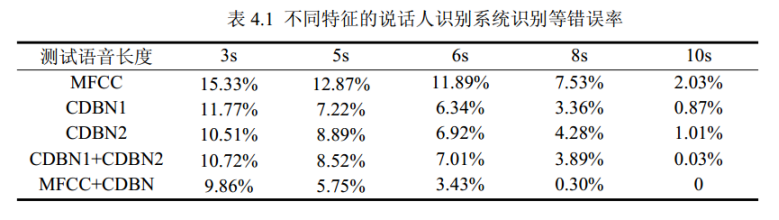
卷积深度置信网络(CDBN)
得分分析
得分分析是将当前用户的声纹特征与数据库中存储的声纹模板进行比对。主要步骤包括:
特征对比:通过计算两组特征向量之间的相似性(如欧氏距离或余弦相似度),判断是否属于同一说话者。
阈值判定:根据设定的阈值,判断匹配结果,决定是否识别成功。