Title: Echo and Narcissus
Creator: John William Waterhouse
Creator Lifespan: 1849/1917
Creator Nationality: British
Creator Gender: Male
Creator Death Place: London, England
Creator Birth Place: Rome, Italy
Date Created: 1903
Physical Dimensions: w1892 x h1092 cm (Without frame)
Type: Oil on canvas
Rights: Purchased in 1903
安全性分析
环境噪音鲁棒性
不同场景下的产品都会有不同的环境噪音,即使是同一产品也会有不同的背景环境,比如智能音箱,在家庭使用和在公司使用,环境噪音也会不一样,在使用声纹识别前需要对这一黑科技的环境噪音鲁棒性进行评估,这一指标表明此技术在不同环境噪音下的适应能力,避免在公司调试时都是好好的,一到用户环境就不灵光了。为了测试声纹识别系统的环境噪音鲁棒性,可以收集产品在不同应用环境下的语音数据进行评测。
信道鲁棒性
信道即为声音信号传输的通道,由于声音从麦克风采集后到声纹识别系统中经过了很多环节,包括有不同的麦克风类型、不同的音频CODEC、不同的传输通道等,这些都会对声纹特征存在影响,还是以智能音箱来举例,假如在注册时是用手机端app,而验证使用时则是直接对着音箱说话,手机MIC和音箱MIC就是两个不同的信道,这种情况下可能会降低验证的准确率,在专业术语上叫信道失配。因此,除了在产品层面做规避,也需要考虑声纹识别技术在不同信道中的表现。
语音内容鲁棒性
我们说话内容都可能包含了数字 、中文、英文,在读特定内容和说口头禅的时候,我们会不自觉表现不一样的说话方式,比如说口头禅或熟悉的话时就会表现得很自然随意,而拿着文稿照着念时,就显得一本正经。在做声纹识别技术评估时,也需要考虑到对语音内容的鲁棒性。
时变鲁棒性
个体变化通过长时的积累,会对个体的发音有特点有影响,进而影响声纹识别系统的识别性能。好的声纹识别系统能在一年,甚至在三年内都不需要重新注册而能正常使用,否则你可能会遇到,三个月前注册了声纹用着都是好好的,三个月后怎么就不认人了呢,这就尴尬了。
表达方式鲁棒性
说话人的表达方式对声纹识别的性能也有影响,比如情感的变化、语速的变化、音量的变化和聊天的区别。还是以智能音箱为例,你在注册声纹时是很开心的,当有一天,你心情不好想和TA聊天时,却怎么也不认你了,这时你砸了TA的心都有了。同样,在做声纹识别评估时都需要考虑到在不同表达方式下的表现。
群体普适性
群体是具有某种(些)共同特征的不同个体组成的集合。不同群体之间存在某些特征的差异,声音上的差异就是其中之一,这种差异会影响声纹识别系统的普适性。这种差异主要体现在性别、年龄、地域划分的不同人群人声纹差异。
假冒攻击防范能力
今年315用照片直接攻破人脸识别系统的事仍让大家对生物识别系统有所担心,同样,声纹识别系统在用声音进行身份认证的过程中,也会存在用假冒声音来企图骗过系统,因此,声纹识别系统应具备活体检测技术,应正确鉴别声音的用户身份,能够拒绝假冒的验证信息,对于利用各种手段形成的假冒声音,应该能正确区分。
如何区分真人的声音和录音设备播放的声音呢,换而言之就是如何防止非真人声音骗过声纹识别系统?我们从产品设计和声音算法两个层面解决这个问题。
在产品设计上,可采用动态密码的方式,比如在验证的时候,显示8位数字,要求验证者在5秒内读完数字,超过5秒后则自动换一组数字,以此方式来防止录音;另外,还可以采用内容与声纹双重验证的方式,即在验证声纹的同时也需要验证内容,以提高被攻击的门槛。 假冒声音攻击主要分类:
在算法上,通过活体检测算法可以有效防止假冒声音攻击。目前,假冒声音攻击主要分为如下四类:
录音重放攻击:攻击者录制目标说话人的语音进行播放,以目标人身份试图通过声纹识别系统的认证。包括直接录音或通过手机实时通话的方式来试图骗过识别系统。
波形拼接攻击:攻击者将目标说话人的语音录制下来,通过波形编辑工具,拼接出指定内容的语音数据,以放音的方式假冒目标说话人,试图以目标人身份通过声纹识别系统的认证。
语音合成攻击:攻击者用语音合成技术生成目标说话人的语音,以放音的方式假冒目标说话人,试图以目标人的身份通过声纹识别系统的认证,
语音模仿攻击:攻击者通过模仿目标说话人,试图以目标说话人的身份通过声纹识别系统的认证。
以上四类假冒声音中,波形拼接、语音合成、语音模仿都是比较容易区分出来。像语音合成,现在的合成技术很难做到和真人声音一样自然连贯,虽然听起来很真实,就像模仿秀那样,听起来非常像,但不等同于一样,在声音活检测算法中一样可以轻易检测出来。
最难检测的是录音重放,因为录音本质上就是真人的声音,只是通过录音设备录下来再播放。然而,通过录音采集编码压缩,再到解码播放,整个流程中已多次对声音进行了有损处理,造成了声音的失真扭曲,与真人的声音已相差甚远,通过活体检测技术一样能区分出来。
当然,如果校真一下,使用高保真监听级录音设备和播放设备,也很大可能骗过声纹识别系统。
基于GAN的声纹合成技术
GAN概念
对抗生成网络自2014年由Goodfellow提出,当时由于其效果不是很显著的原因一直导致学术界没有过多的关注,自从2015年末到2016年末,在深度学习的蓬勃发展下,对抗生成网络也借此春风卷土重来。
对抗生成网络是一个通过对抗的过程来估量生成模型(Generative Model)。
通过给出的一组训练样本,生成模型可以构建一个或一些分布来解释训练样本出自何处。生成模型可简单分为两种方式:第一个是密度估计,简单的一维的数据集(比如数据点)可以通过计算密度公式来描述概率分布。第二个就是常见的样本生成,通过大量的训练数据生成一个机器来生成新的来自同一分布的样本。
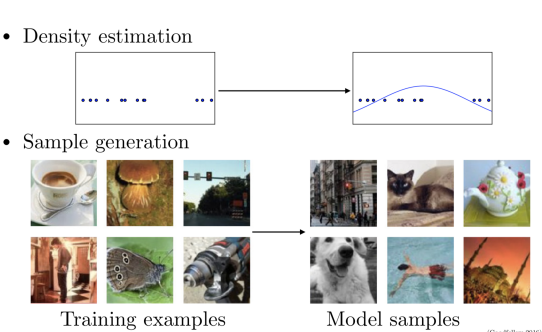
虽然通过反向传播喝丢弃算法,深度学习的判别模型具有良好梯度的分段线性单元,但由于最大似然估计和相关策略中遇见许多难以解决的概率计算困难,并且在生成上下文事很难充分利用分段线性单元的好处,导致深度生成模型影响力并不是很好。因此GAN能够很好的解决这些问题。
GAN基本思想
对抗生成网络(Generative Adversarial Networks,下称GAN)启发自博弈论中的二人零和博弈(two-player game),在二人零和博弈中,两位博弈方的利益之和为零或一个常数,即一方有所得,另一方必有所失。而在对抗生成网络中,这两个博弈方的角色会分别有生成式模型(generative model)和判别式模型(discriminative model)
具体方式为:生成模型G捕捉样本数据的分布,判别模型D时一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率。G和D为一般的非线性映射函数,例如多层感知机、卷积神经网络等,这样,就找到了一个可以和深度学习相互结合的点。
数学思想:假设有一种概率分布M,它相对于我们是一个黑盒子。为了了解这个黑盒子中的东西是什么,这里构建了两个东西G和D,G是另一种我们完全知道的概率分布,D用来区分一个事件是由黑盒子中那个不知道的东西产生的还是由我们自己设的G产生的。
一句话描述—“D和G的训练是关于值函数的极小化极大的二人博弈问题(two-player game)”。
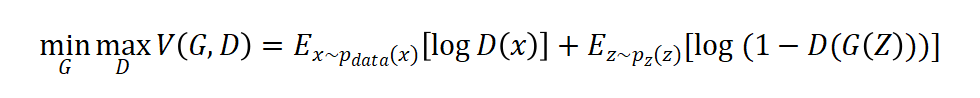
其中表示x属于真是的训练数据, 代表x来自于真实数据分布,我们训练D来最大化分配正确标签的概率,不管数据是来自于训练样例还是G生成的样例。我们同时训练G来最小化。
其中$x~P_{data}(x)$表示$x$属于真实训练数据,$z~p_{z}(z)$ 表示$z$取自我们模拟的分布,$D(x)$代表$x$来自于真实数据分布,我们训练D来最大化分配正确标签的概率,不管数据是来自于训练样例还是G生成的样例。我们同时训练G来最小化$log(1-D(G(z)))$。
实际上,以上方程可能无法为G提供足够的梯度来学习。训练初期,当G的生成效果很差时,D会以高置信度来拒绝生成样本,因为它们与训练数据明显不同。
因此,$log(1-D(G(z)))$饱和。所以我们选择最大化$log(D(x))$而不是最小化$log(1-D(G(z)))$来训练G,该目标函数使G和D的动态固定点相同,并且在训练初期,该目标函数可以提供更强大的梯度。
StarGAN-VC
语音转换(VC)是一种在保留语言信息的同时转换指定话语的语言信息的技术。VC可以在很多地方得到应用,如文本到语音(TTS)系统的说话人身份(男女,老少等)修改, 口语辅助,语音增强和发音转换。
VC的发展也是一直在进步,应用较为广泛的就是基于高斯混合模型(GMM)的发展。这几年随着深度学习的铺开,RNN, GAN以及基于非负矩阵分解(NMF)在VC上也到了应用和发展。但是大部分的VC方法需要精确的将源语音信号和目标语音信号做严格配对,这就使得在一般情况下, 收集这些并行话语是相当困难的。然而即使可以收集这些并行数据,也需要执行时间对齐的操作,当源语音和目标语音之间存在较大的声学间隙时,这种对齐操作就会很麻烦。
目前VC的方法大部分对于并行数据中涉及的对齐处理不是很理想,因此可能需要仔细的预筛选和手动校正才能使这些框架可靠地工作。为了绕过这些限制, StarGAN关注的是实现一种非并行VC方法,它对训练集的要求上既不需要平行话语,也不需要时间对齐造作。
这样使用非并行语音训练在已有的方法上得到的转换后的语音质量和转换效果通常是有限的,实现具有与并行方法一样高的音频质量和转换效果的非并行方法是非常具有挑战性的。
自动语音识别(ASR)的方法大大改善了非并行语音转换,但是这种方法很大程度上取决于ASR的好坏,一旦ASR不稳定整个模型将无法正常工作。还有一些方法的提出, 比如i-vector,但这种方法在语音转换的身份上受限。在深度学习上, CVAE在非并行语音转换上是成功的,CVAE我想熟悉生成模型的都知道,通过控制条件向量C完成语音间的转换,但是一个问题就是VAE在decoder的结果上是平滑的, 也就是生成的数据有一定模糊,这就导致了转换后的语音的质量不高。
我们都知道GAN生成数据是很sharp的,这就是VC的另一个突破点,StarGAN作者就是利用GAN的思想不断完善VC。 StarGAN之前作者还写了一篇CycleGAN-VC,目的旨在学习声学特征从一个属性X到另一个属性Y的映射G和它的逆映射F,后面我们再展开说。
CVAE和CycleGAN虽然在并行数据的要求上没这么多限制但是在测试时必须知道输入语音的属性。对于CVAE-VC,源属性标签c必须被馈送到训练的CVAE的编码器中, 对于CycleGAN-VC,训练和测试时间的源属性域必须相同。VAE-GAN在很多方面都是较为优秀的,但是训练的不稳定是提出StarGAN的一个优势。
vector quantized VAE (VQ-VAE)在VAE的基础上使用了Wavenet网络,在处理非并行数据有了很大的提高,但是也带来了计算量的庞大,需要的训练样本较多。
以上的种种问题,诞生了StarGAN,一个集美貌与才华为一身的存在。
StarGAN同时具有CVAE-VC和CycleGAN-VC的优点,但与CycleGAN-VC和CVAE-VC不同的是StarGAN-VC的生成器网络G 可以同时学习多对多映射,其中发生器输出的属性是由辅助输入c控制。与CVAE-VC和CycleGAN-VC不同,StarGAN-VC使用对抗性损失进行生成器训练,以鼓励生成器输出与真实语音无法区分,并确保每对属性域之间的映射将保留语言信息,StarGAN-VC在测试时不需要任何有关输入语音属性的信息。
最后,总结一下StarGAN的优点:
- 既不需要并行语音同时转录也不需要语音生成器训练的时间对齐
- 可以同时在单个发生器网络中学习使用不同属性域的多对多映射
- 能够足够快的生成转录语音的型号以允许实时实现
- 仅需要几分钟的训练示例来生成合理逼真的语音
CycleGAN-VC模型介绍
我们一起来看一下CycleGAN-VC的模型结构图:
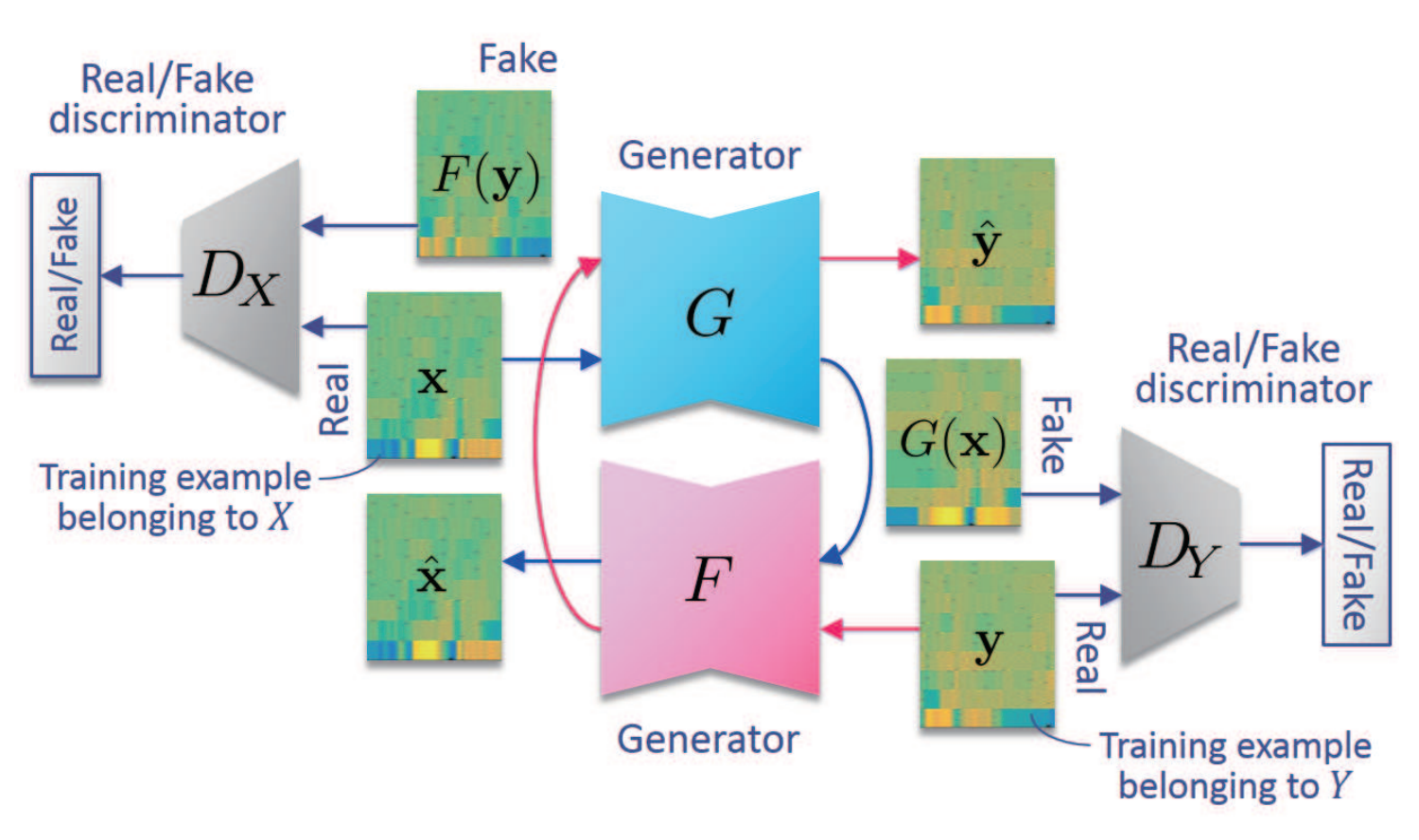
其实CycleGAN-VC在整体框架上和CycleGAN处理图片是一致的,只是输入从图像到图像换成了音频到音频而已。大概流程为:音频通过网络生成音频,音频通过F网络生成音频,音频与生成的送入判别器判断真假,音频与生成的送入判别器判断真假。为了实现循环(Cycle)的思想,将生成的送入网络得到,同样的将生成的送入网络得到。因为是存在两个生成器,两个判断器,所以对抗损失也有两个;为了保障循环生成的质量,还有一个循环损失。
另外,论文中提到加入了一个额外的损失:身份损失(identity-mapping loss)。循环一致性损失会对结构产生约束;但是,仅保证映射始终保留语言信息是不够的。为了让语言信息能够完整保存,因此需要生成器找到保留输入和输出之间组成的映射。所以我们引入了identity-mapping loss这个知识。最终我们的所有loss的公式为:
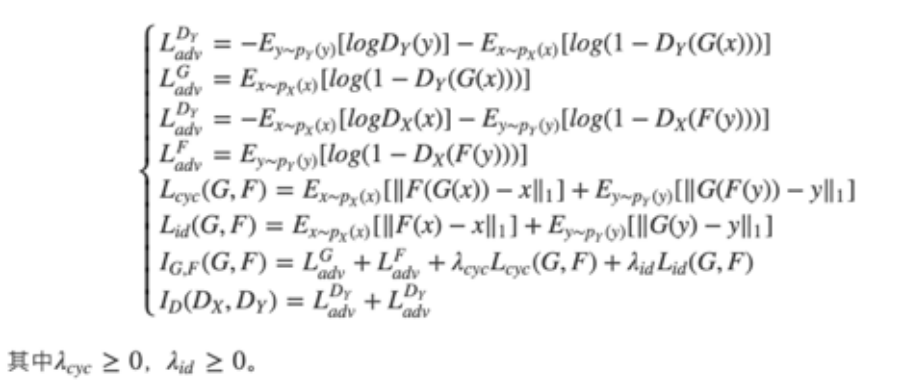
StarGAN-VC模型介绍
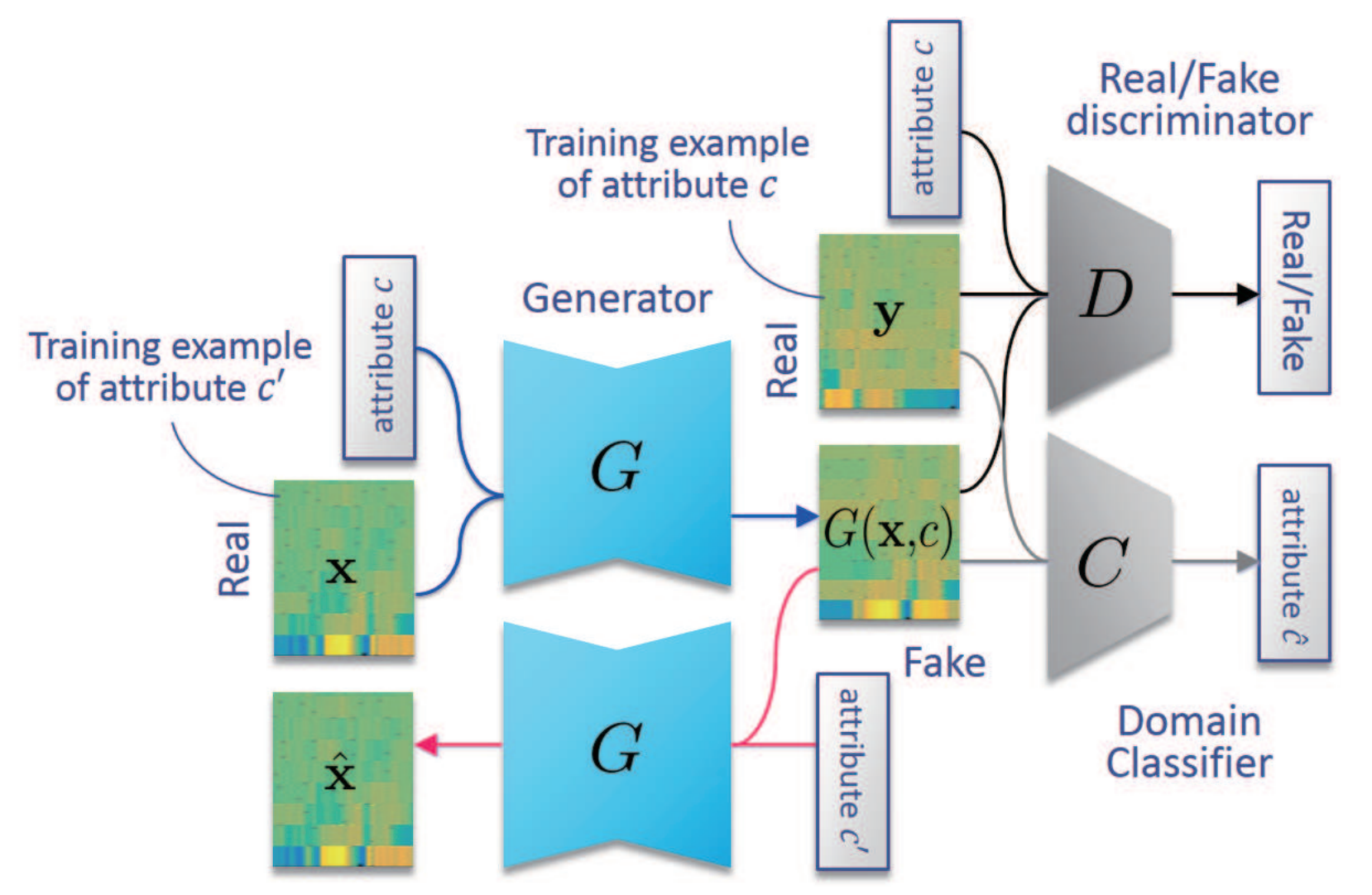
与CycleGAN-VC不同的是StarGAN-VC生成器和判别器只有一个,但是可以实现不同属性的声音的生成。
我们以一段原始音频为例,如果给定男性的属性C, 那么经过网络后会生成出男性的音频。
我们从头分析一下模型,整个框架有3部分组成,生成器G,判别器D,分类器C。一段音频xx加上属性cc 经过生成器G得到具有属性cc的音频G(x,c),属性c下的真实音频y与生成音频G(x,c) 送入判别器判断真假,此时为了保证属性也还需要属性标签c 的参与。
为了很好的将属性标签分开,训练了分类器C,通过优化标签c和属性音频的匹配达到分类器的优化,从而让每一个属性音频之间可以很好的区别, 同时也让生成的属性音频之间尽可能的有各自的属性特点。同样的为了达到循环优化的目的G(x,c) 在原始音频属性c′经过生成器G可以得到x̂, 最后为了保证特征学习,再加上一个身份损失(id loss)。整个网络大方向上有生成器G的损失,判别器D的损失和分类器C的损失。
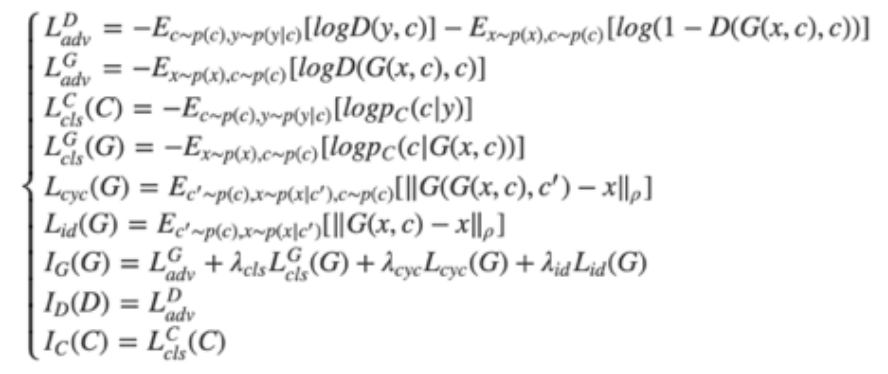
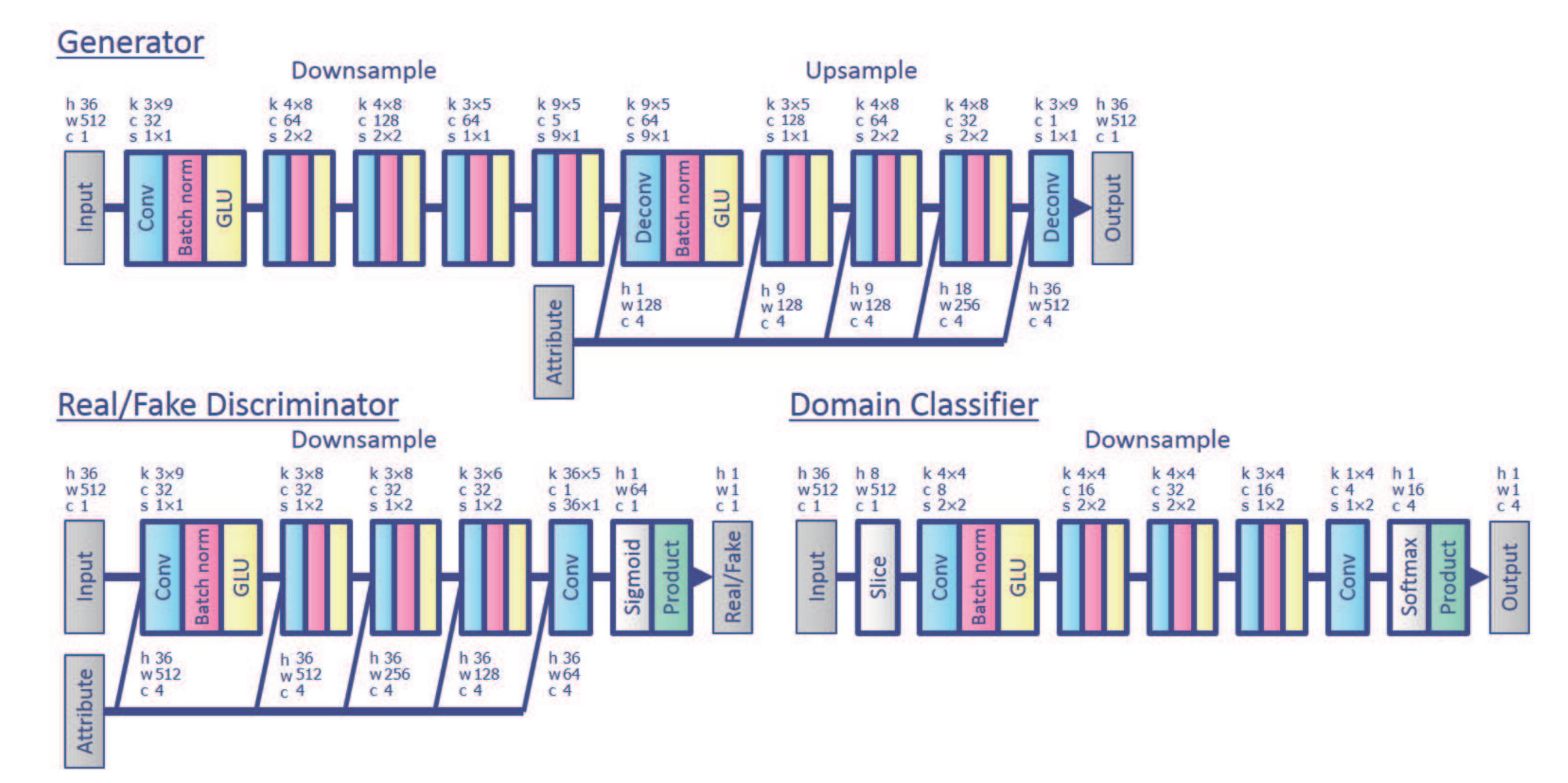
音频之间转换的核心也是将音频转换为声谱图文中称之为声学特征序列,利用图像到图像的关系实现最终的转换。一旦生成的谱增益函数就可以通过频谱增益函数与输入语音的频谱 包络相乘并且通过声码器重新合成信号来重建出时域的语音信号。
所以整个模型框架采用CNN搭建起来,但是为了保证声谱图的结构性,论文用了GatedCNN为主要手段, 文中称其优于LSTM。下面为整个框架的网网络结构设计:
内部实验:StarGAN-VC实验
数据准备
本次实验使用的源代码为Hujinsen根据论文复现的基于tensorflow代码,使用的训练集和验证集是VCC2016发布的平行语料库vcc2016_training和evaluation_all。
其中,vcc2016_training 有五个说话源和五个目标说话人。(’S’ denotes ‘source’, ‘T’ denotes ‘target’, while ‘M’ and ‘F’ for ‘male’ and ‘female’, respectively.)。每个人录了162句话(约7分钟)。音频文件名从100001到100162,不同说话人录的相同id的音频文件内容相同。验证集同样是五个人每个人录了54句话。
其中我们使用的训练集和验证集选了其中两位男士和两位女士 (“TM1”, “TM2”, “SF1”, “SF2”)。我们使用所有的训练集来提声学特征(mcep, f0, cep)并在训练过程中随机挑选evaluation_all的文件完成语音转换。
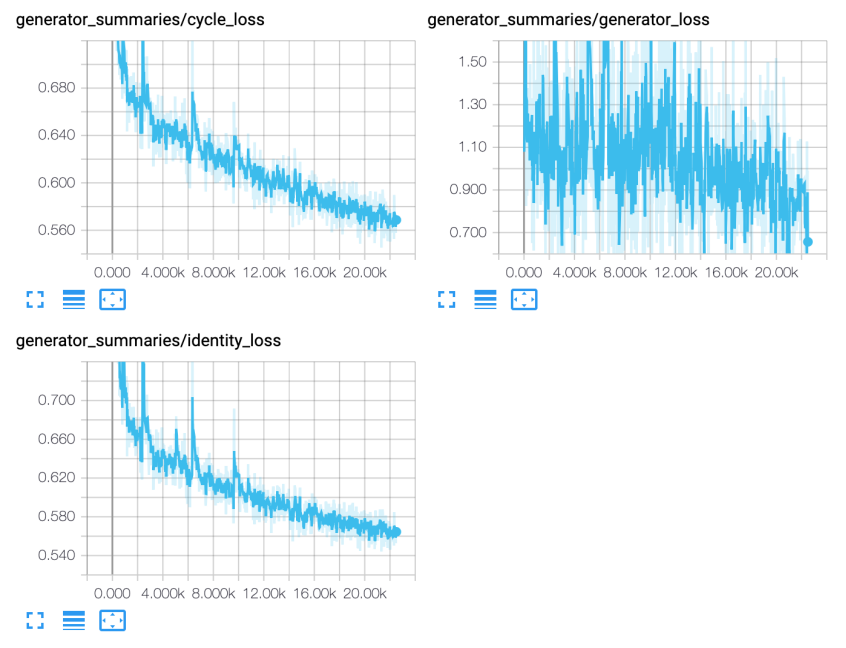
实验结果
本次实验用了1000个epoch 和 22500+ steps,各种损失函数图像如下:
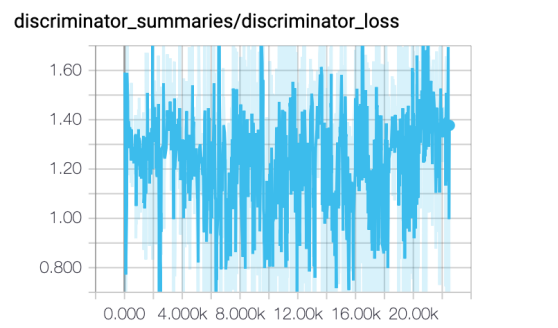
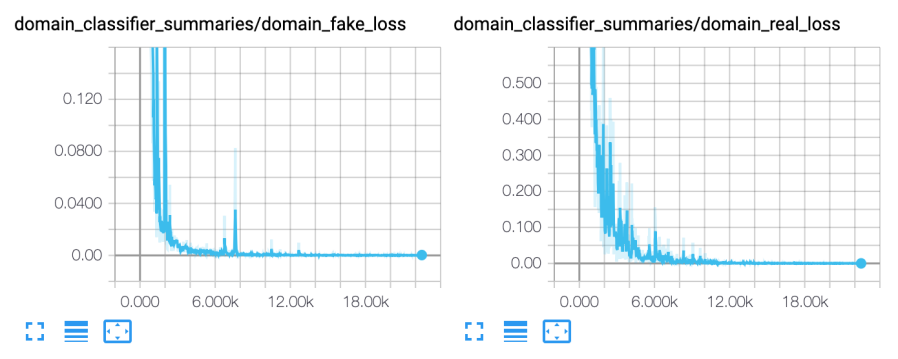
存在的问题
- 当到达300个epoch左右之后发现生成的语音文件没有明显的改变,观察音频波形图发现相似度极高,可能遇到了mode collapse的问题。
- 损失函数并未出现converge,可能是训练不够或者出现non-convergence的情况。
- 生成的语音并没有官方的效果好。
真人与回放音分辨技术
概述
在生物识别技术领域,声纹识别系统因安全性较高,获取较为方便,在生活领域、金融领域以及司法领域得到了广泛应用。声纹识别技术不断发展的同时,各种仿冒语音对声纹系统的攻击也日趋严峻。
在过去的几年中,研究人员对仿冒语音的检测主要集中在合成语音和转换语音的上, 一定程度上忽视了回放语音对声纹识别系统的攻击。事实上,由于回放语音是通过真实声音直接录音得到的,因此比合成语音和转换语音更具有威胁性。
其次,回放语音相较于其他仿冒语音获取更为方便,仅仅需要一部录音设备就可以完成为仿冒者提供了便利。同时近些年高保真设备的普及化和便携化,更是极大的提升了回放语音对声纹识别系统的威胁。
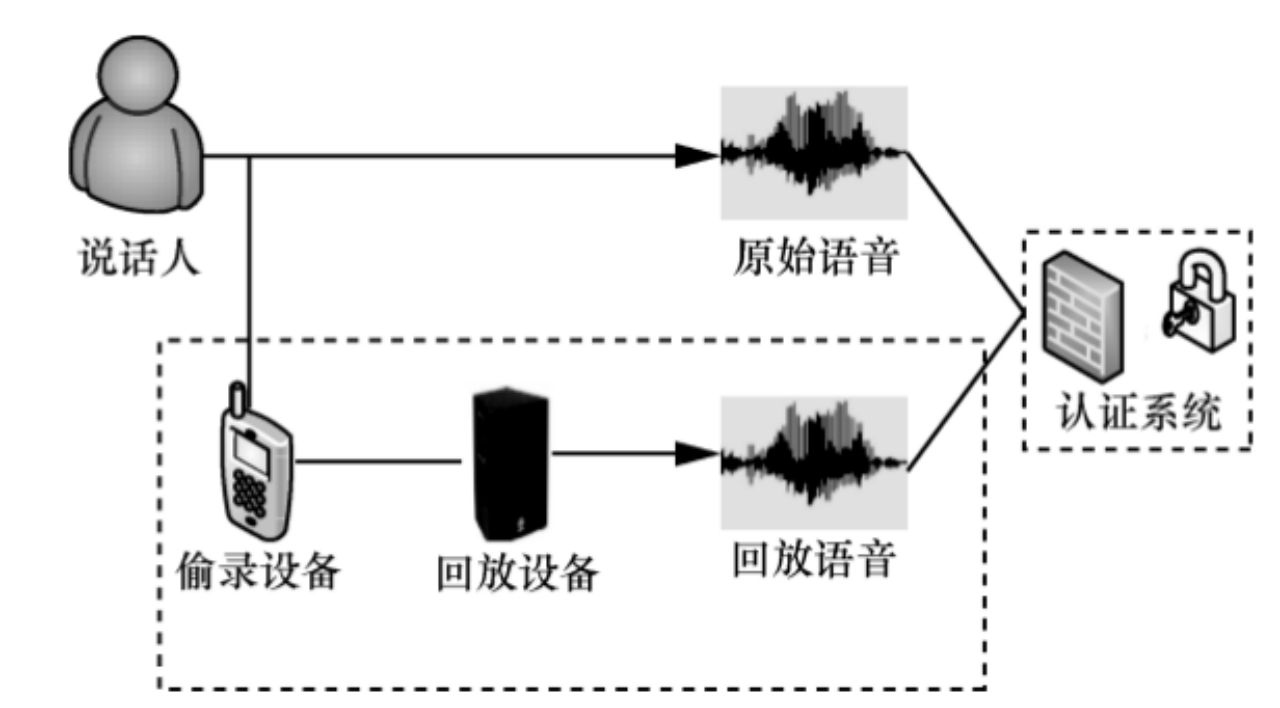
下图展示了回放语音产生的过程。
回放攻击检测,可以分为传统机器学习方法与深度学习方法。
传统的机器学习方法,多为人工设计的特征,如CQCC,MFCC作为输入,通过GMM,SVM等分类器判断输入样本是真实语音还是回放语音。
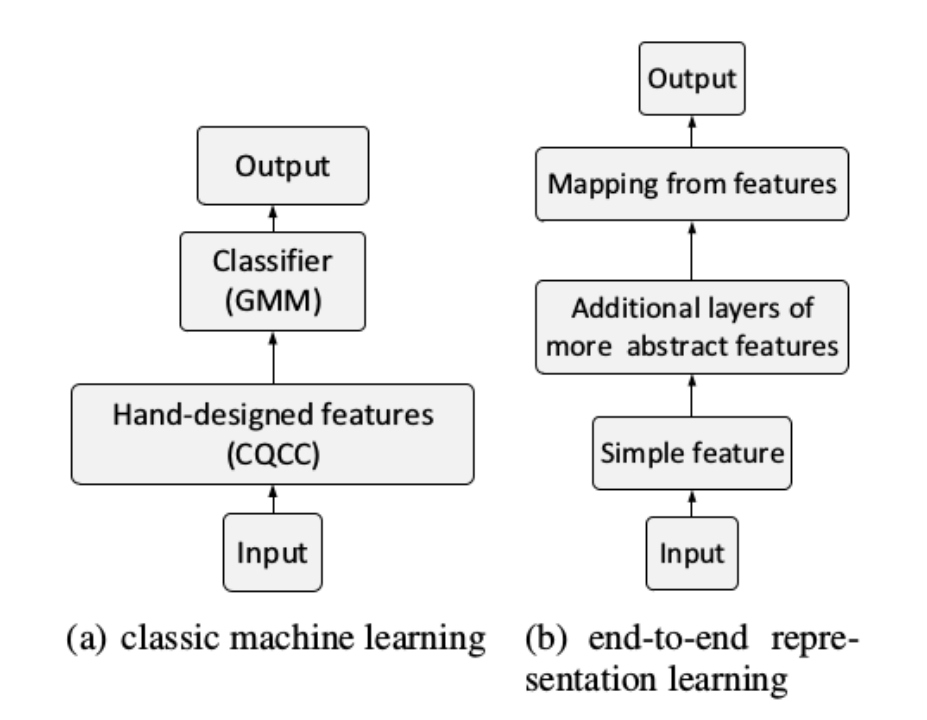
深度学习方法,对频谱特征输入通过神经网络提取了更具有表征性的特征,这一特征更能反应真实语音与回放语音之间的区别。其流程图如图所示。
特征提取
提取语音信号的频谱特征是信号处理中常见的特征提取方法。图显示了一段真实语音与回放语音的频谱图。回放攻击检测中常见的频谱特征如下。
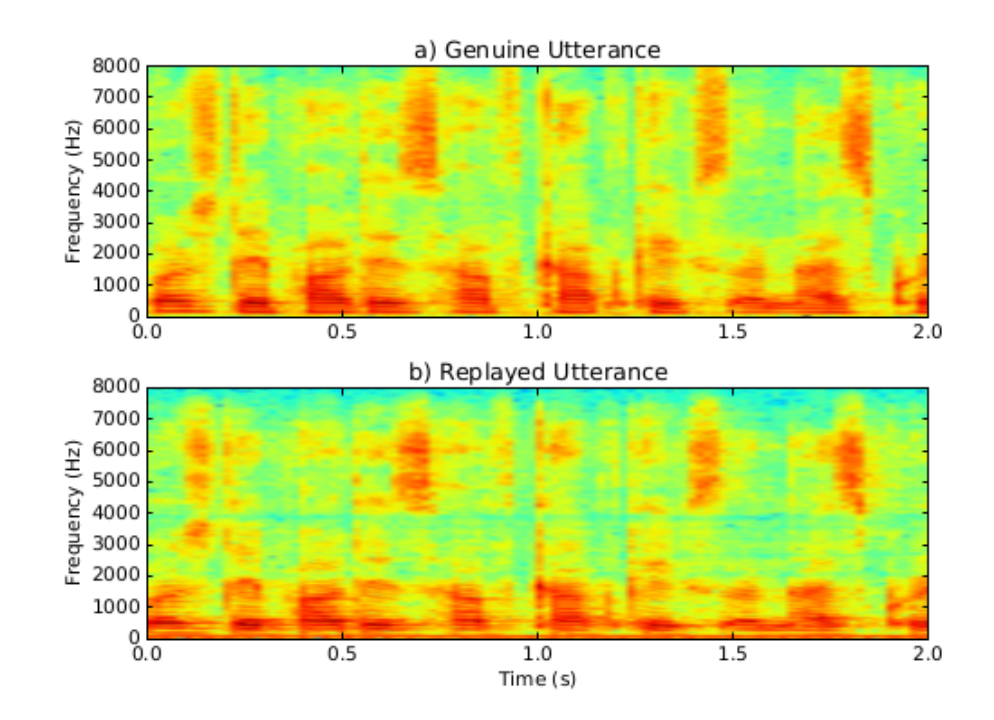
“Birthday parties have cupcakes and ice-cream”真实语音与回放语音频谱
CQCC
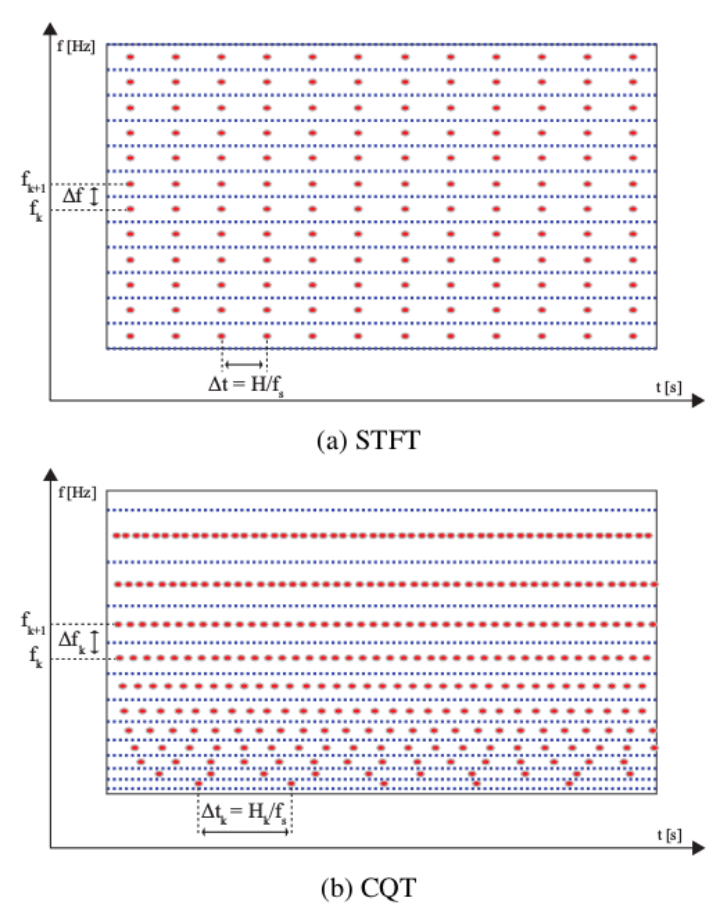
CQCC(Constant Q Cepstral Coefficients),测不准原理:$\Delta f \Delta t ≥ 1/4 \pi $ 的限制,我们不可能同时在频域和时域获得高的分辨率。由此发展出来short-term Fourier transform为代表的分析技术。STFT的Q因子却随着频谱移向高频而增大,而人的听觉系统的Q因子是一个大致处于500Hz到200KHz的常数。
为了模拟人的听觉系统,提出了CQT(constant Q transform)。CQT与DFT的对比如图:

Constan Q变换与傅里叶变换的对比
CQCC是基于CQT的一种频谱特征。
一个离散时序信号x(n)的CQT为:
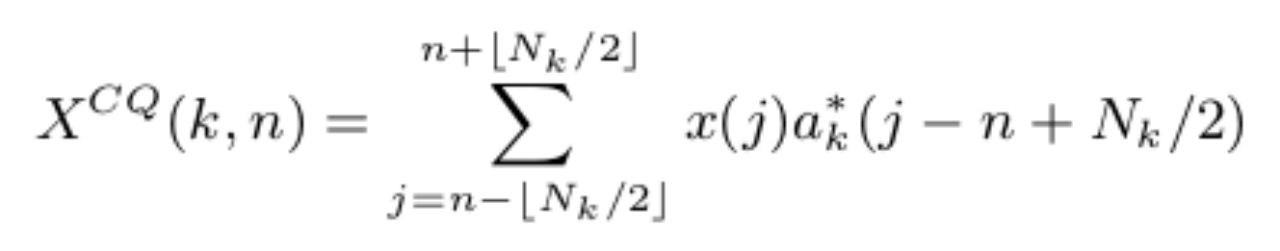
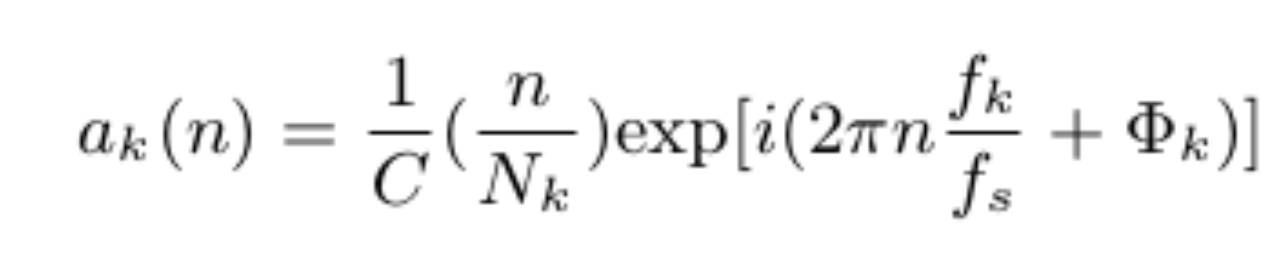
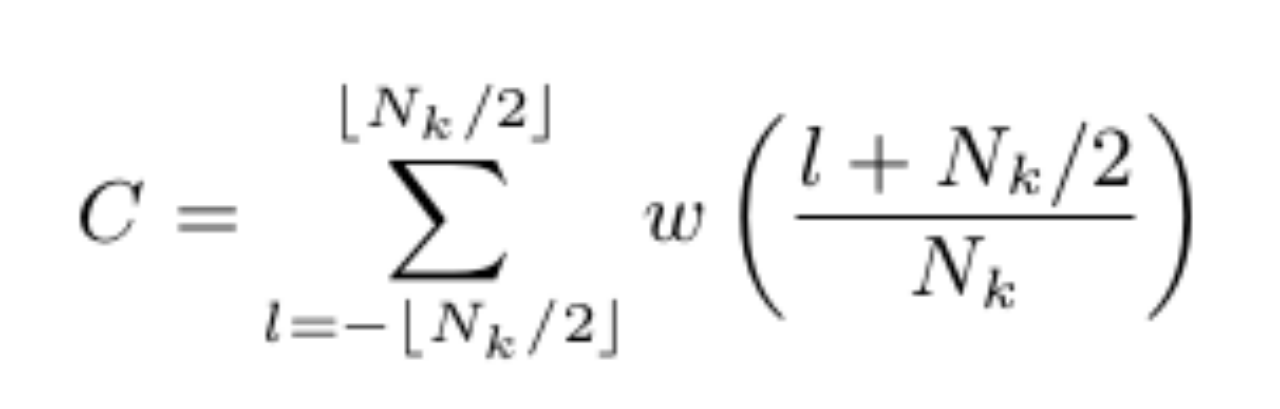
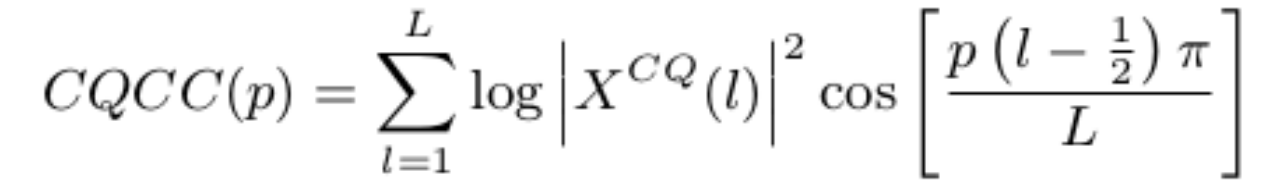
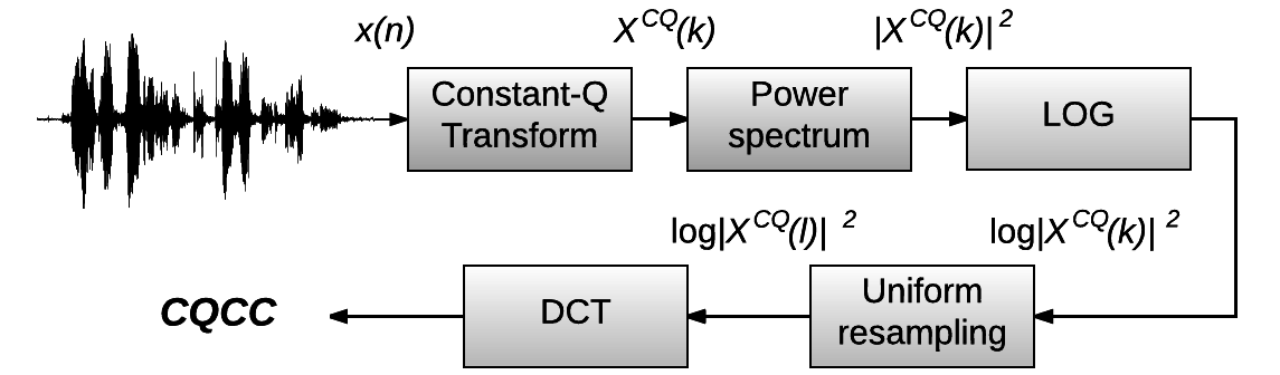
CQCC的提取流程如图所示:
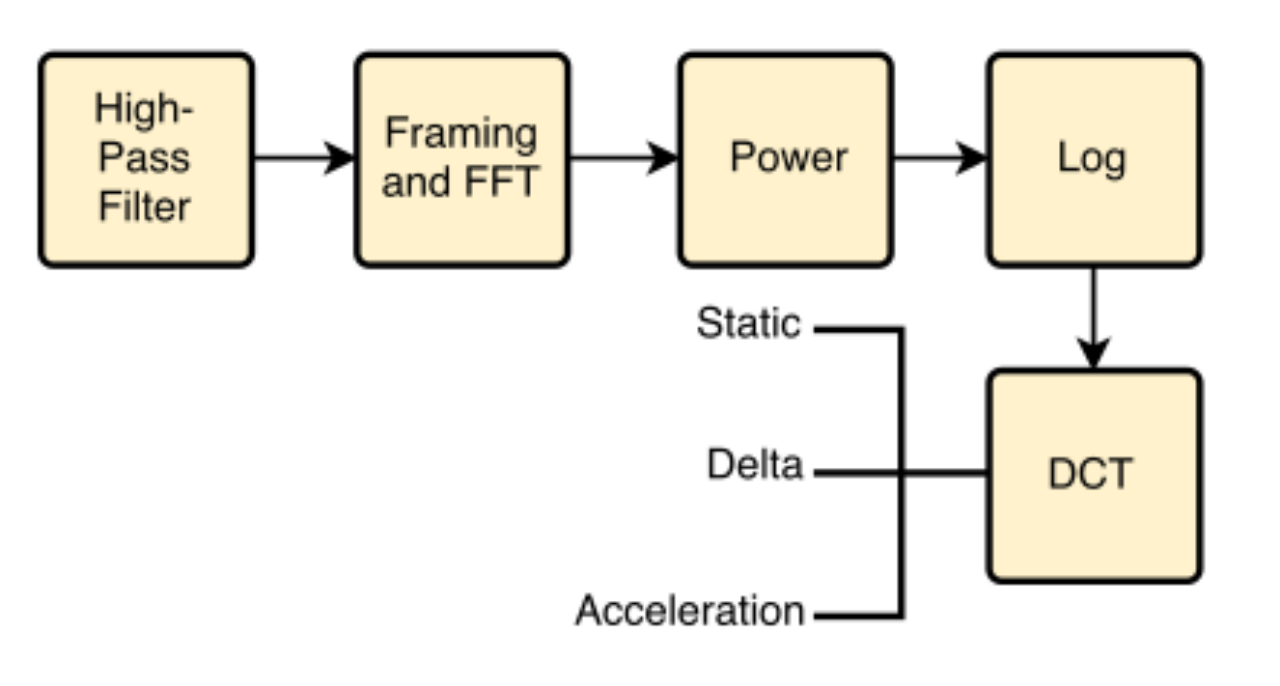
HFCC
High-Frequency Cepstral Coefficients其提取流程图如图
其它特征
包括Cepstrum、MFCC、IMFCC、LPCC、LPCCres、I-vector。
传统机器学习方法
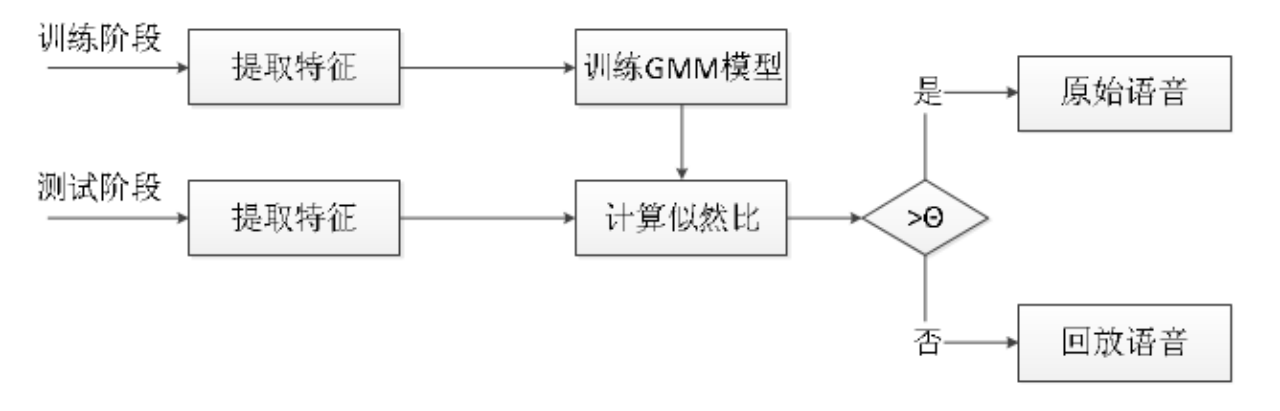
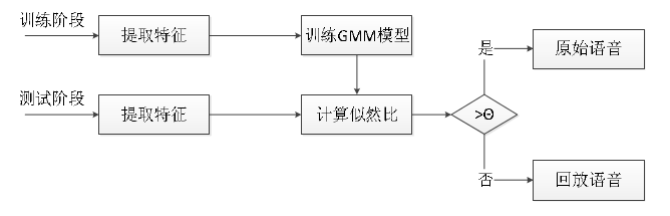
在训练阶段,首先提取训练集语音的特征,然后训练两个 GMM 模型。一个是原始语音的 GMM 模型(记作λt ),另一个是回放语音的 GMM 模型 (记作λf )。在测试阶段,将提取语音的特征向量 X 在两个 GMM 模型下计算似然比σ ,似然比定义如下:
$ \sigma = log(P(x|λt)/P(x|λf)) $
用得到的似然比作为得分来判决待测的语音和哪个模型更匹配。 最后我们通过设定一个阈值 θ 进行最后的分类判断。流程图如图所示。

$P(fa)(θ) $表示在阈值 $θ$ 处的虚警率, 反映被判定为原始语音的样本中,有多少个是回放语音
$P(miss)(θ)$表示在阈值$ θ $处的漏警率,反映的是有多少个原始语音被判定为回放语音
$P(fa)(θ)$和$P(miss)(θ)$分别是关于$ θ$单调减和单调递增的函数。通过调节阈值 $θ $的取值可以调节虚警率$P(fa)(θ)$和漏警率$P(miss)(θ)$。
若使得虚警率降低,则漏警率就会变大。反之若降低漏警率,则虚警率就会相应的提升。因此对于阈值的选择,可根据实际情况进行调节。如果在高安全性在训练阶段, 则可以通过调节阈值使得虚警率最小,以提高安全性。若用于诸如考勤等低安全性领域,则可以适当降低阈值以提另一高漏警率,以兼顾易用性。
分类器
GMM、SVM、DNN。GMM是一种生成式模型,DNN是判别式模型,I-vector/SVM是两种模型的结合
深度学习方法
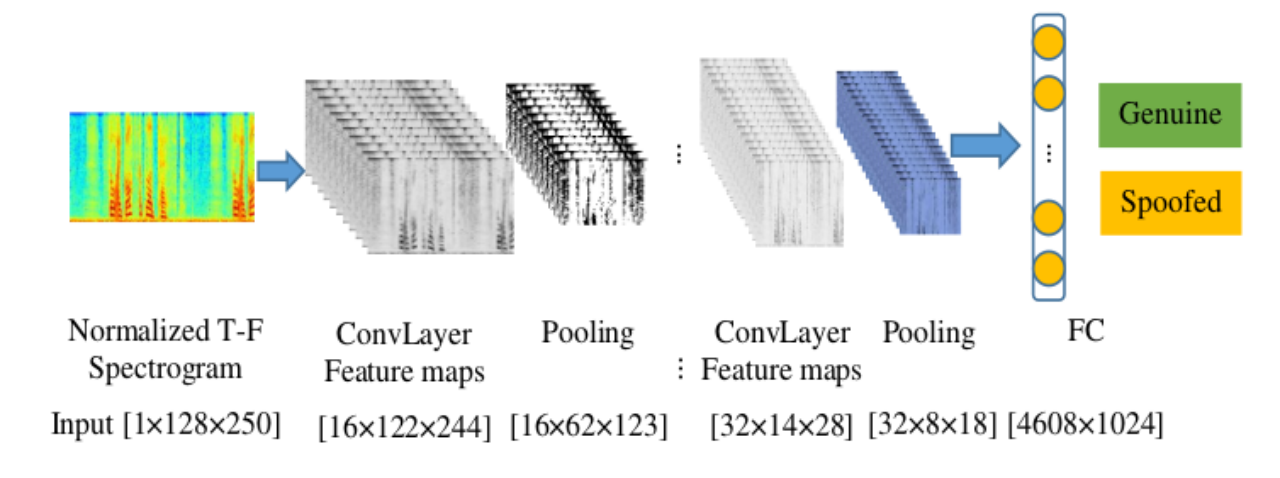
CNN
基于卷积神经网络的回放攻击检测如图所示。
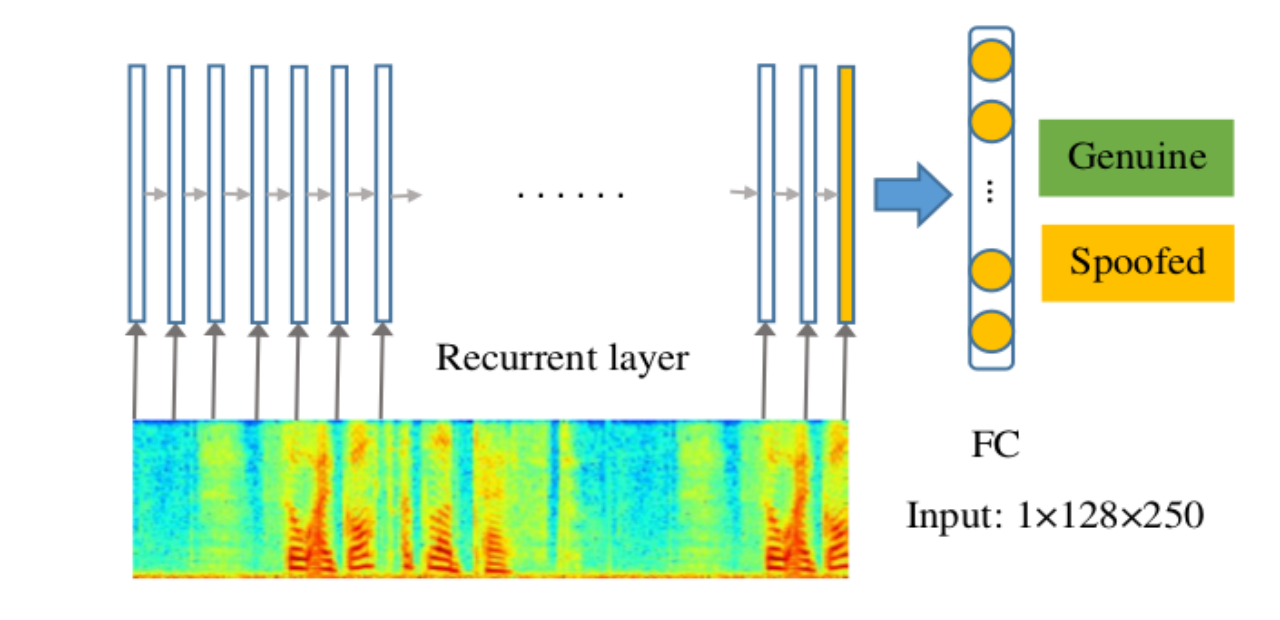
RNN
基于RNN的回放攻击检测如图所示。
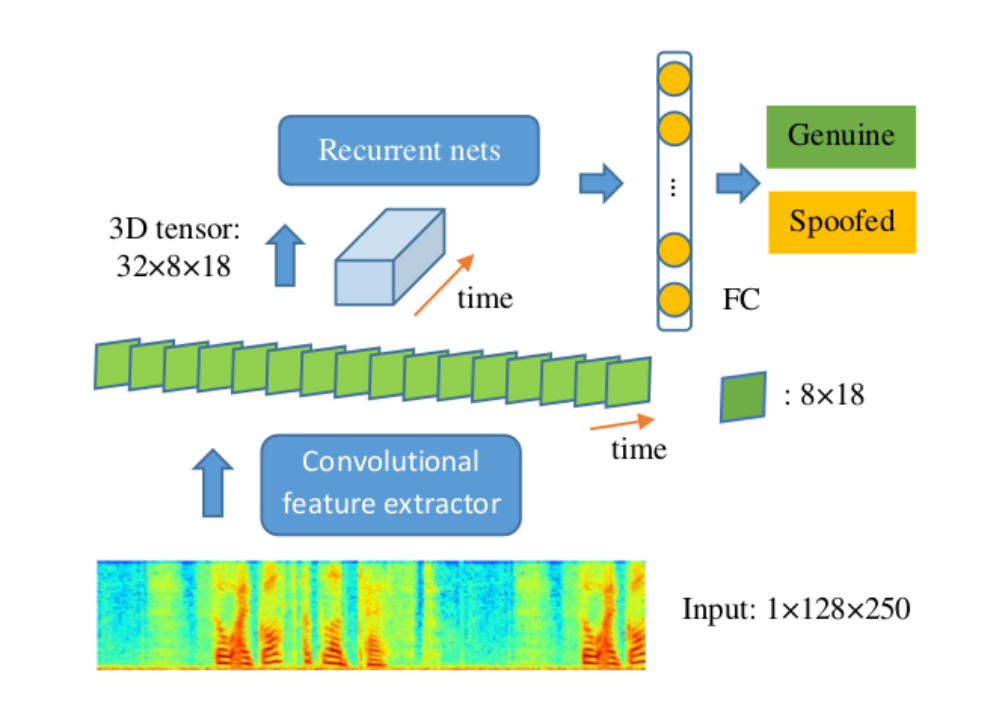
CNN+RNN
将CNN与RNN结合的回放攻击检测如图所示。
CQCC+HFCC+CNN
将CQCC与HFCC同时作为底层特征输入,结合CNN的回放攻击检测如下图所示:
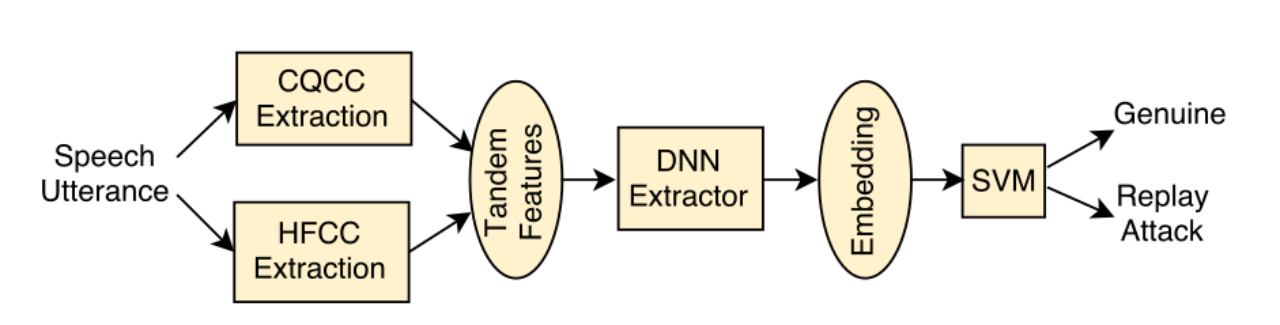
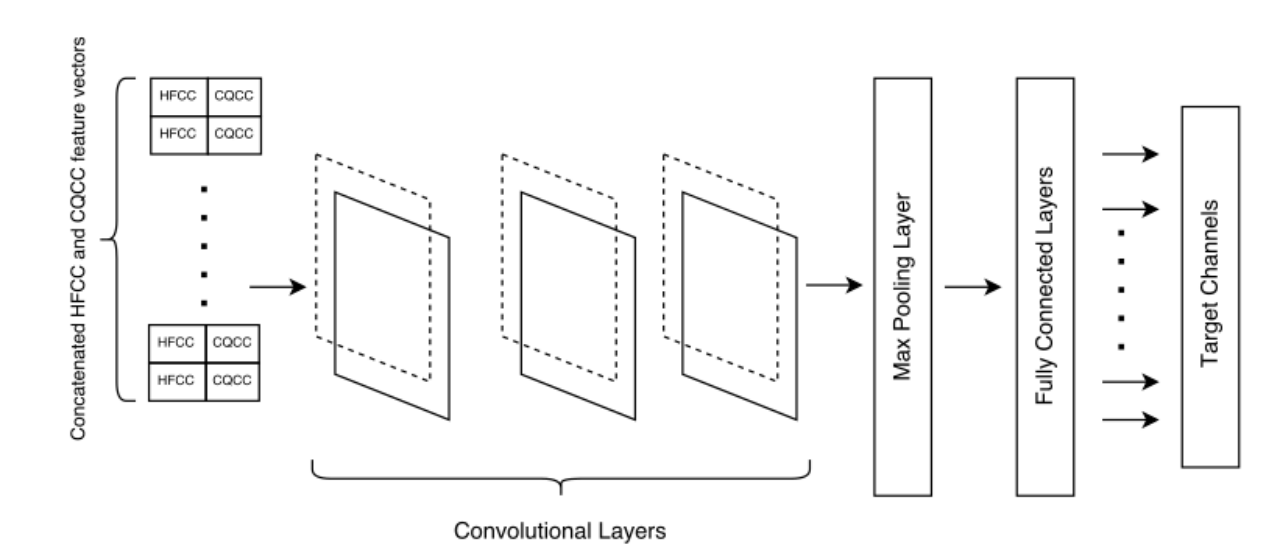
其网络网络结构如下图所示。
内部实验:语音回放攻击检测
数据集
ASVspoof 2017 Version 2.0
算法思路
算法流程:
特征提取:
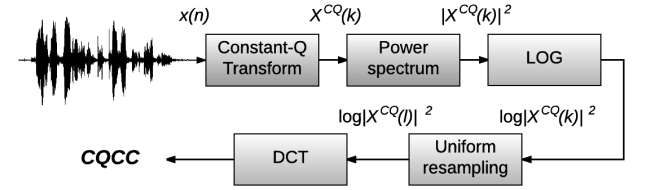
回放攻击检测的算法流程如上图1所示,特征提取采用CQCC,其提取流程如上图2
在训练阶段,首先提取训练集语音的特征,然后训练两个GMM模型。一个是原始语音的GMM模型(记作λt ),另一个是回放语音的GMM模型 (记作λf )。
在测试阶段,将提取语音的特征向量X(CQCC)在两个 GMM 模型下计算似然比σ ,似然比定义如下:
$ \sigma =log(P(x|λt )/P(x|λf)) $
用得到的似然比作为得分来判决待测的语音和哪个模型更匹配。 最后我们通过设定一个阈值$θ$进行最后的分类判断。
实验配置
运行环境:Ubuntu16.04
软件:matlab2017b
实验效果
EER 13.44%